Phần mềm chuyển văn bản thành giọng nói offline
Giọng đọc AI tự nhiên, truyền cảm
Không rập khuôn robot đại trà. Mỗi giọng được huấn luyện riêng biệt — sắc nét, chân thực và đầy cảm xúc.
Bảo mật kịch bản tuyệt đối
Kịch bản và dữ liệu âm thanh không bao giờ rời khỏi thiết bị của bạn. Không server. Không cloud.
Không giới hạn ký tự
Đầu tư một lần duy nhất. Sử dụng trọn đời, không phát sinh chi phí theo ký tự hay phí dịch vụ hàng tháng.
Chạy Offline 100%
Hoạt động hoàn toàn không cần kết nối internet. Nhanh, ổn định, độc lập hoàn toàn.
Danh mục giọng AI
Mỗi giọng là một tài sản số độc lập — đầu tư một lần, sở hữu vĩnh viễn, không phí API.
Premium Studio
48kHz · Ultra-Low LatencyBroadcast Series
24kHz · Standard LatencyVocalisVN-Nâng Cao-01
Giọng Bắc · Nam24kHz · Latency <200ms
Không gian làm việc chuyên nghiệp & Hiệu năng thực chiến
Trải nghiệm giao diện Studio tối giản và kiểm tra tốc độ xử lý âm thanh độc lập ngay trên thiết bị của bạn.
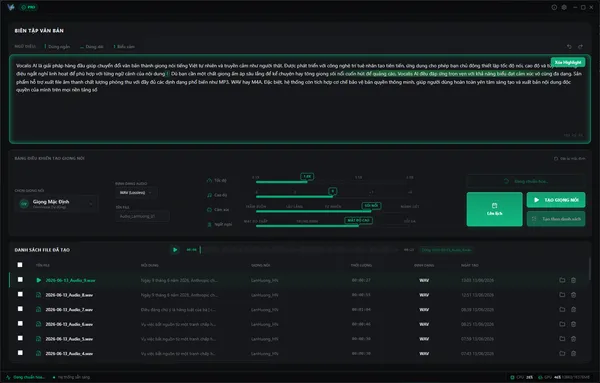
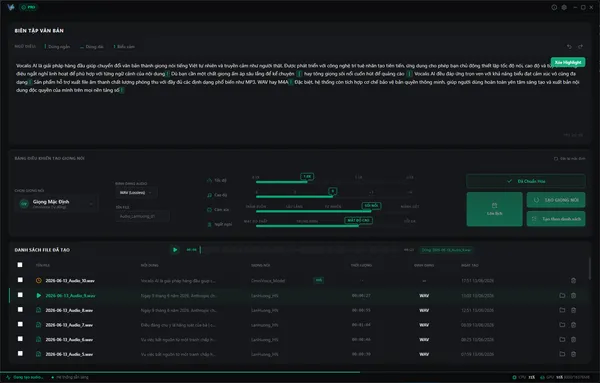
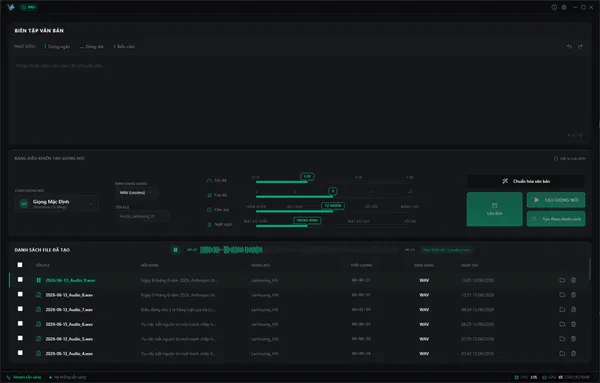
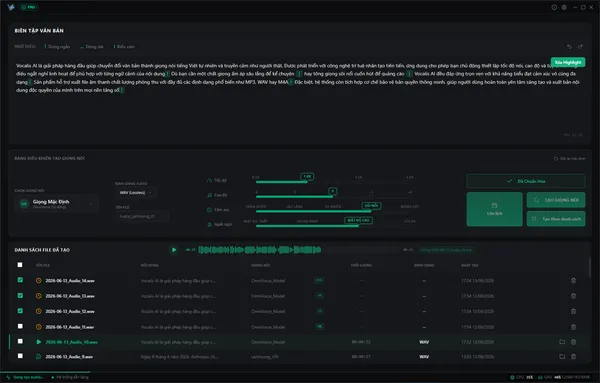
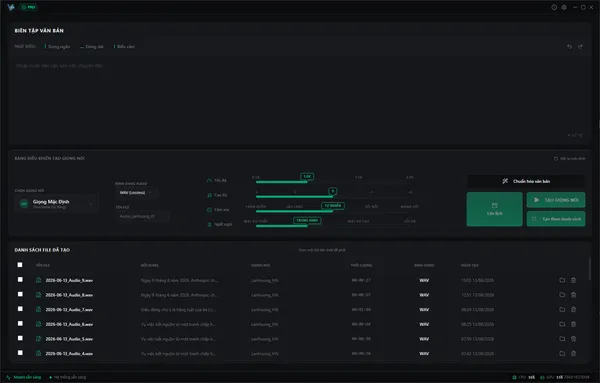
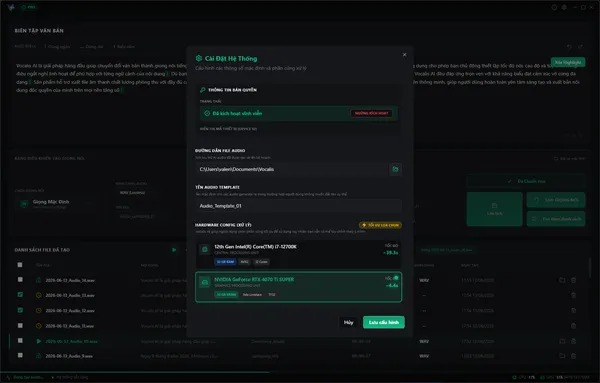
Giao diện minh họa · Thiết kế thực tế có thể khác
Chuẩn hóa AI
Tự động chuẩn hóa văn bản, từ viết tắt và định dạng số trước khi đọc.
Tinh chỉnh linh hoạt
Điều chỉnh tốc độ, cao độ, cảm xúc và ngắt nghỉ tự nhiên.
Hẹn giờ thông minh
Lên lịch và chạy chuyển đổi văn bản sang audio hàng loạt tự động.
Đa dạng định dạng
Hỗ trợ xuất chất lượng cao WAV, MP3, FLAC chuẩn phòng thu.
Tối ưu phần cứng
Tự động phân bổ hiệu năng CPU/GPU tối ưu hóa tốc độ render.
Chuẩn Studio
Giao diện trực quan dạng dòng thời gian giúp kiểm soát dễ dàng.
Dự tính tốc độ xử lý audio của máy bạn
* Ước tính dựa trên benchmark Vocalist model, văn bản tiếng Việt 60s. Kết quả thực tế dao động ±10–15% phụ thuộc vào tải hiện tại của thiết bị.
Xử lý xong 1 phút audio với
Triển khai dễ dàng. Vận hành ngay lập tức.
Quy trình 3 bước tối giản giúp bạn làm chủ hạ tầng âm thanh độc quyền mà không cần kiến thức kỹ thuật phức tạp.
Lựa chọn giọng đọc
Chọn mô hình giọng AI độc quyền phù hợp với đặc thù dự án hoặc nhận diện thương hiệu của bạn từ danh mục.
Bàn giao & Kích hoạt trọn gói
Đội ngũ kỹ thuật chuyên trách sẽ tiến hành cài đặt, tối ưu cấu hình phần cứng và kích hoạt hệ thống hoàn toàn miễn phí. Chúng tôi cung cấp tài liệu hướng dẫn vận hành chi tiết và cam kết bảo hành kỹ thuật toàn diện trong 03 tháng kể từ thời điểm bàn giao.
Toàn quyền sản xuất
Nhập kịch bản, tự do tinh chỉnh sắc thái cảm xúc và xuất bản hàng loạt audio chất lượng cao offline 100% trọn đời.
Đừng trả phí cho mỗi ký tự
bạn tạo ra
Lựa chọn gói giải pháp tối ưu phù hợp với quy mô sản xuất của bạn.
Trải nghiệm & Thử nghiệm cá nhân
- Sở hữu ngay 3 giọng đọc tiêu chuẩn chất lượng cao
- 10 ngày trải nghiệm trọn vẹn toàn bộ tính năng cao cấp
- Tự do sáng tạo, không giới hạn nội dung và số lượng ký tự
Triển khai nội bộ · Tự chủ hạ tầng
- Sở hữu trọn đời 3 giọng đọc tiêu chuẩn sắc nét
- Sở hữu vĩnh viễn toàn bộ tính năng của VocalisVN
- Tạo âm thanh không giới hạn nội dung và ký tự
- Tối ưu hóa phần cứng vượt trội, tăng tốc xử lý tối đa
Giọng nói AI độc quyền thương hiệu & doanh nghiệp
- Tự do lựa chọn giọng đọc bản quyền yêu thích trong thư viện
- Tạo & sở hữu giọng nói AI độc quyền thương hiệu cho doanh nghiệp
- Đặc quyền hỗ trợ kỹ thuật chuyên sâu 24/7
- Cập nhật và nâng cấp tính năng trọn đời
Công cụ dự tính hoàn vốn
≈ 1.620.000 ký tự / tháng
* Quy đổi nhịp điệu tiếng Việt: 150 từ/phút × 6 ký tự/từ (gồm dấu câu/khoảng trắng) → 1 giờ audio ≈ 54.000 ký tự.
Chi phí Cloud ước tính
~340.200đ / tháng
Trung bình: ~150.000đ – 200.000đ / 1M ký tự (Tham khảo từ Vbee, FPT.AI, Zalo AI...)
Hoàn vốn sau
Tháng · so với Cloud API
Tối ưu cho nhu cầu sử dụng > 10 giờ / tháng
Tại sao doanh nghiệp chọn
giải pháp của chúng tôi?
Pháp lý minh bạch & Được bảo hộ
Mọi model giọng nói đều tuân thủ các chuẩn mực đạo đức AI cao nhất. Hợp đồng sở hữu trí tuệ được thiết lập chặt chẽ, đảm bảo quyền khai thác độc quyền trọn đời cho bạn.
Cỗ máy vận hành độc quyền (Proprietary Engine)
Thay vì các mô hình mã nguồn mở đại trà, chúng tôi vận hành trên kiến trúc AI đã qua tinh chỉnh độc quyền, tối ưu hóa cho cảm xúc và sắc thái riêng biệt mà không một API công cộng nào có được.
Quyền sở hữu & Bảo mật (Zero-Data-Retention)
Thiết kế hướng tới sự tự chủ (Sovereignty). Bảo vệ kịch bản và dữ liệu âm thanh độc quyền của bạn ngay trên thiết bị nội bộ, đảm bảo quyền sở hữu tuyệt đối trong suốt quá trình sản xuất.
Tư vấn triển khai 1:1
Lộ trình cá nhân hoá cho doanh nghiệp & nhà sáng tạo.
Nền tảng AI thế hệ mới
Kiểm soát sắc thái, nhịp điệu, cảm xúc với độ chân thực cao.
Hạ tầng Local · Uptime 24/7
Không phụ thuộc Internet. Hiệu suất ổn định, không biến động.
Sẵn sàng đầu tư vào
giọng nói của bạn?
Mỗi ngày trì hoãn là mỗi ngày đối thủ xây dựng lợi thế nhận diện thương hiệu trên bạn. Đội ngũ chuyên gia của chúng tôi sẵn sàng phân tích nhu cầu và thiết kế lộ trình triển khai phù hợp — hoàn toàn miễn phí.
Câu hỏi thường gặp
Giải pháp có hoạt động hoàn toàn offline không?
Có. Toàn bộ model giọng nói chạy trực tiếp trên máy chủ hoặc thiết bị của bạn. Dữ liệu văn bản và file âm thanh không bao giờ rời khỏi hệ thống nội bộ — không có kết nối cloud, không có API bên thứ ba trong quá trình vận hành thực tế.
Mất bao lâu để triển khai một giọng nói tùy chỉnh?
Thông thường 7–14 ngày làm việc kể từ khi hoàn tất thu âm mẫu. Quy trình gồm: thu âm dữ liệu gốc → fine-tuning model → kiểm thử chất lượng → bàn giao. Thời gian có thể rút ngắn hoặc kéo dài tùy theo độ phức tạp của yêu cầu.
Tôi có sở hữu hoàn toàn model giọng nói sau khi đầu tư không?
Có. Sau khi hoàn tất hợp đồng, bạn nhận được file model và quyền khai thác độc quyền trọn đời. Hợp đồng sở hữu trí tuệ được ký kết đầy đủ, đảm bảo không bên thứ ba nào có thể sử dụng giọng nói của bạn.
Giải pháp hỗ trợ những ngôn ngữ nào?
Hiện tại chúng tôi tối ưu hóa cho tiếng Việt (cả 3 miền Bắc, Trung, Nam) và tiếng Anh. Các ngôn ngữ khác như Nhật, Hàn, Thái đang trong giai đoạn phát triển — vui lòng liên hệ để biết lộ trình cụ thể.
Chi phí duy trì hàng tháng là bao nhiêu?
Không có phí duy trì định kỳ. Đây là khoản đầu tư một lần — bạn trả tiền để sở hữu hạ tầng, không phải thuê dịch vụ. Không có token fee, không có subscription, không có giới hạn số lượng ký tự xử lý.
Tôi cần chuẩn bị gì để bắt đầu?
Để tạo giọng nói tùy chỉnh: cần khoảng 2–4 giờ thu âm trong môi trường yên tĩnh với micro chất lượng tốt. Để triển khai model có sẵn: chỉ cần máy chủ Linux/Windows với RAM tối thiểu 8GB. Đội ngũ của chúng tôi sẽ hỗ trợ toàn bộ quá trình cài đặt.
Không tìm thấy câu trả lời? Liên hệ trực tiếp với chúng tôi →